智能软件研究中心发布了目前学术界最大的零售场景目标检测计数任务数据集——Locount,该数据集包含的商品实例标注数量达到190万个;同时,针对被检测物体高度重叠场景中,无法通过传统检测框区分和计数的问题,给出了完整的基础解决方案和新的评估标准,有利于解决复杂场景下的目标检测和计数问题,也同样适用于现实场景中长尾分布、少样本学习等多个潜在研究方向。相关工作被国际人工智能大会AAAI 2021收录。为了解决实际的工业应用问题并推动该问题的学术研究,我们完整地提出了研究本任务的必需元素:问题定义,数据集,评价标准和基准算法。
问题定义
目标检测任务通常使用一个矩形框来预测单个目标的位置。为了去掉重复预测,通常使用非极大值抑制方法进行后处理。如图1(c)所示,这种表示方法并不适用于商品零售场景,因为同一类别商品重叠摆放会存在严重遮挡的现象,在实际使用中也没有必要精确定位每一个实例目标。因此,我们重新思考并定义了在该场景下的目标检测任务。具体来说,如图1(d)所示,如果多个目标是相互严重遮挡且属于同一个类别,我们预测该目标簇中所有目标框合并的最小包围框及对应的实例数量。

图1 传统目标计数(a)和目标检测(b)数据集中采样的标注图片;(c)传统的检测标注应用到我们的数据集的呈现形式;(d)我们提出的检测标注方式在我们的数据集上的呈现方式。
数据集
为了解决新任务,我们提出了迄今为止最大的商品零售场景下的Locount数据集。如图2所示,该数据集包含超过50000 张图像和190万商品实例。其中每个标注框包含了同类商品实例及其数量,与其他商品类型数据集相比,具有明显优势。
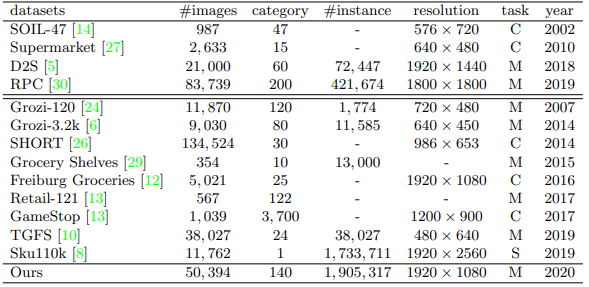
图2 零售场景数据集对比。
* *
我们在28家大小型商场和超市进行了广泛地货架商品收集和整理,并综合沃尔玛、京东、物美等超市的主流分类方法,将货架商品数据集分为9个大类别,即,婴儿用品(例如:婴儿尿布、婴儿拖鞋)、饮料(例如:果汁、姜茶)、食品(例如:鱼干、蛋糕)、日用化学品(例如:肥皂、洗发水)、服装(例如:夹克、成人帽)、电器设备(例如:微波炉、插座)、存储用具(例如:垃圾桶、凳子)、厨房用具(例如:叉子、食品盒)、以及文具和体育用品(例如:滑冰鞋、笔记本)。如图3所示,每个大类别又进一步划分为若干个子类别,一共包括140种常见的商品,基本覆盖超市中的常见商品种类。
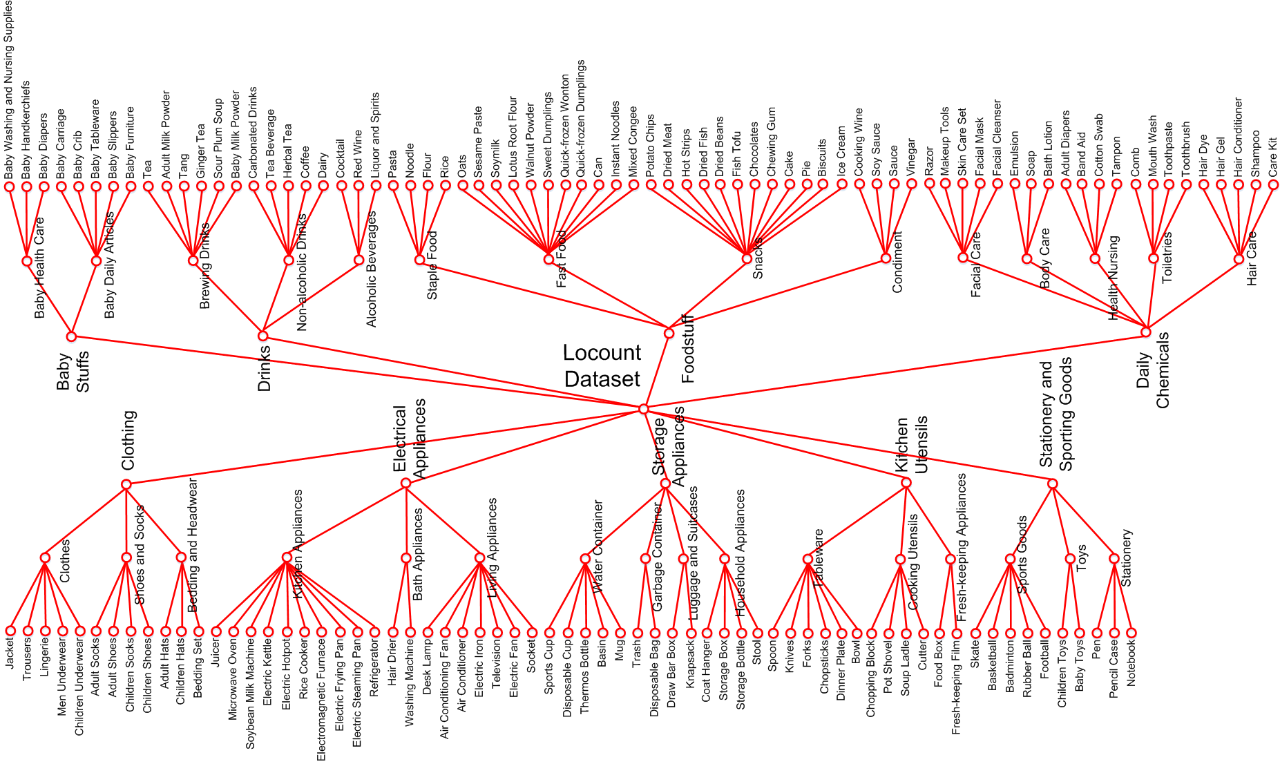
图3 locount数据集商品类别树状图。
评价标准
为了评估不同算法在该任务上的性能,我们设计一种新的评价标准以反映算法出现目标丢失、对同一实例的重复检测、错误检测、错误计数等情况。在MS COCO的评估标准基础上,我们使用新设计的指标 以及 来对检测器进行评估。具体来说,一个准确的检测器应该满足两个标准,(1)预测的边界框 和真实的边界框 之间的交并比( )大于阈值 ;(2)包含在预测边界框中的预测实例数 与真实的实例数 之间的计数准确率( )大于阈值 。此外我们对所有类别在10个不同IoU阈值和10个不同AC阈值下求平均值 ,( ,步长为0.05, ,步长为0.05。)作为评测算法性能的主要指标。
基准算法
我们在Cascade R-CNN的基础上提出一种级联的目标检测和计数网络来解决商品检测和计数的新任务。如图4所示,该网络随着IoU和计数阈值的增加,逐步对目标边界框回归和分类,并同时对边界框中的实例数进行估计。具体来说,预测图片送入主干网络中进行特征提取,然后使用一个建议子网络(表示为“ ”)来生成初步的目标框建议。在此基础上,执行多阶段的定位与计数,即将 进行级联,生成N阶段具有分类分数和实例数量的目标边界框集合。也就是说,目标特征被输入到三个级联的全连接层中(即类别分类层、目标框回归层以及实例计数层)来产生最后的结果。在训练过程中,用于生成正负样本的第i阶段的定位IoU阈值设置为 ,其中, 是预定义的增量参数。
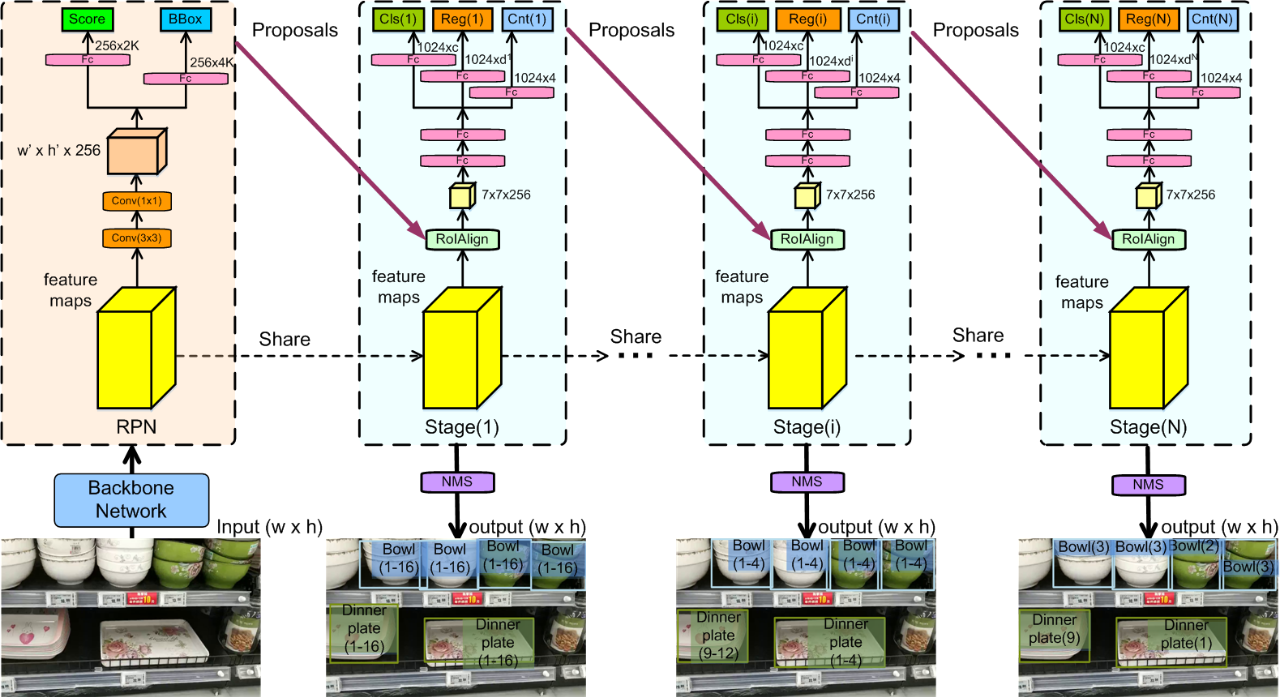
图4 定位和计数的协同商品检测模型。
和Cascade R-CNN不同,本文首先提出对于实例计数预测的简单策略,即,使用全连接层以浮点数表示来回归实例个数,称为计数回归方法。然而,包含在边界框中的实例数量是一个整数,因此,对于网络来说要精确地回归这个整数是一个挑战。因此,我们设计了一个新颖的 “计数分类策略”来解决这个问题。具体来说,我们假设一个目标簇中包含实例的最大数量为α,则构造α个箱(bin)来表示实例个数。从而将目标计数的回归任务转化为分类任务,使用一个全连接层来确定箱的索引。同样的,我们设计了一个级联网络由粗到细地逐步逼近实例的准确数量。我们使用 来表示在第 阶段新划分的类别数。到第 阶段时,我们一共有 种类别。为了覆盖所有可能的实例数量,需要保证 。方便起见,我们使用数字基表示来确定每个阶段的计数划分(即分类任务中的箱数)。以二进制表示为例,如果最大实例数α=50,网络包含3个阶段(N=3),6位数字基足以覆盖所有可能的实例数( )。在每个阶段,我们可以逐步覆盖2位以上的数字,将实例个数的取值空间划分为4个以上的部分。具体来说,在第一阶段,我们只关注实例个数的前两位数字(即00,01,10和11)来生成正负样本。在第二阶段,我们再覆盖两位数字,并用前4位数(即0000,0001,0010,…,1111)来生成正负样本。以此类推。通过这种方式,实例个数的取值空间可以被划分成4个、16个和64个不同的部分,构造从粗粒度到细粒度的处理过程来获得更精确的计数结果。另外,八进制、十进制或其他进制也能够在级联架构中用于计数划分,可以在具体应用中择优选择。如图5所示,基于二阶段十进制的算法CLCNet-s(2)-cls(10)取得最好效果43.5% ,超过基于全连接层估计计数的算法CLCNet-s(2)-reg,以及基础算法Cascade R-CNN的性能。实验表明了本文提出算法的有效性,且明显提高在严重遮挡的商品检测和计数任务中的精度。
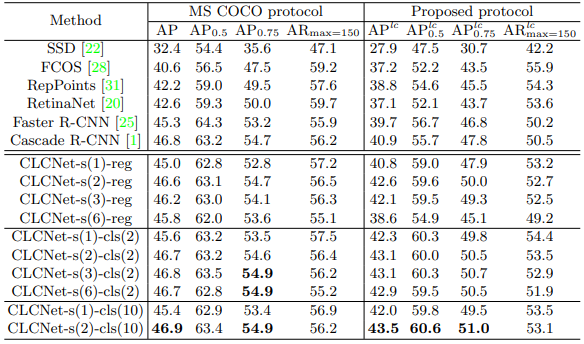
图5 商品检测和计数结果对比。
论文下载地址:
https://isrc.iscas.ac.cn/gitlab/research/locount-dataset/-/blob/master/AAAI2021_CLCNet.pdf
数据集下载地址及密码:
https://pan.baidu.com/s/13JJAHz2VXD0KewdcemfsXQ#list/path=%2F fyze
