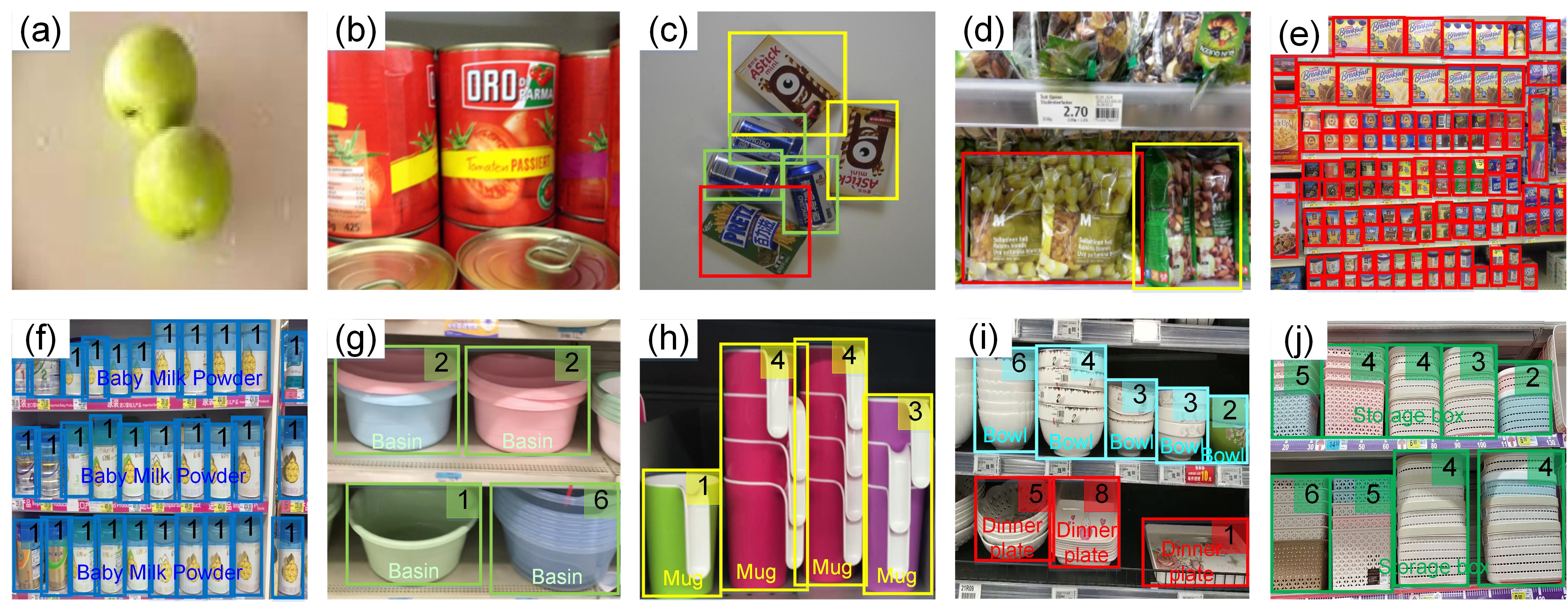
Figure 1: The previous object recognition datasets in grocery stores have focused on image classification, i.e., (a) Supermarket Produce (Rocha et al. 2010) and (b) Grozi-3.2k (George and Floerkemeier 2014), and object detection, i.e., (c) D2S (Follmann et al. 2018), (d) Freiburg Groceries (Jund et al. 2016), and (e) Sku110k (Goldman et al. 2019). We introduce the Loccount task, aiming to localize groups of objects of interest with the numbers of instances, which is natural in grocery store scenarios, shown in the last row, i.e., (f), (g), (h), (i), and (j). The numbers on the right hand indicate the numbers of object instances enclosed in the bounding boxes. Different colors denotes different object categories.
## Locount dataset To solve the above issues, we collect a large-scale object localization and counting dataset at 28 different stores and apartments, which consists of 50,394 images with the JPEG image resolution of 1920x1080 pixels. More than 1.9 million object instances in 140 categories (including *Jacket*, *Shoes*, *Oven*, etc.) are annotated.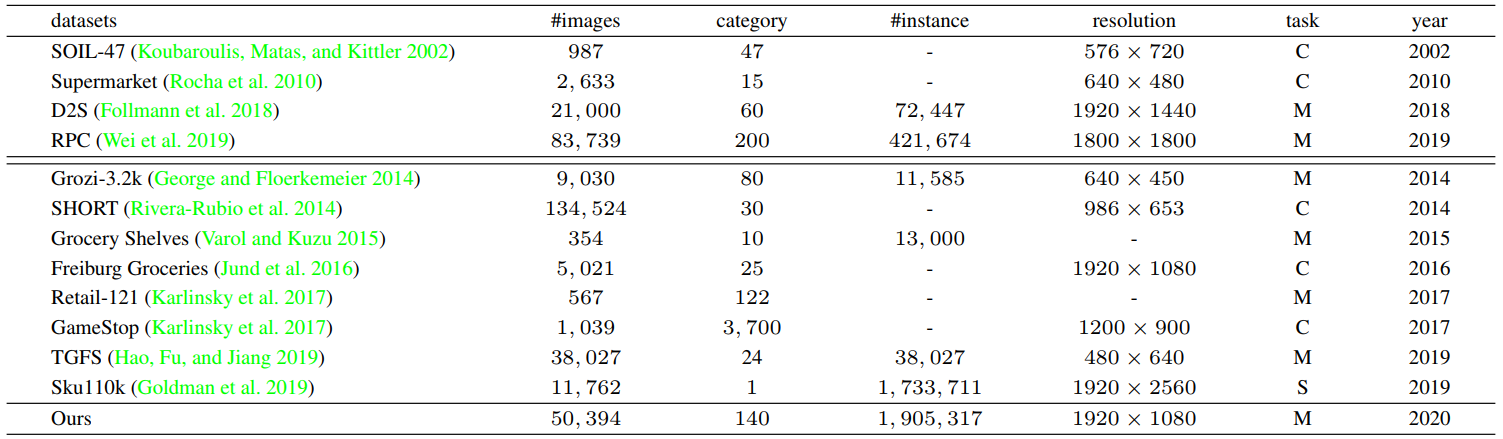
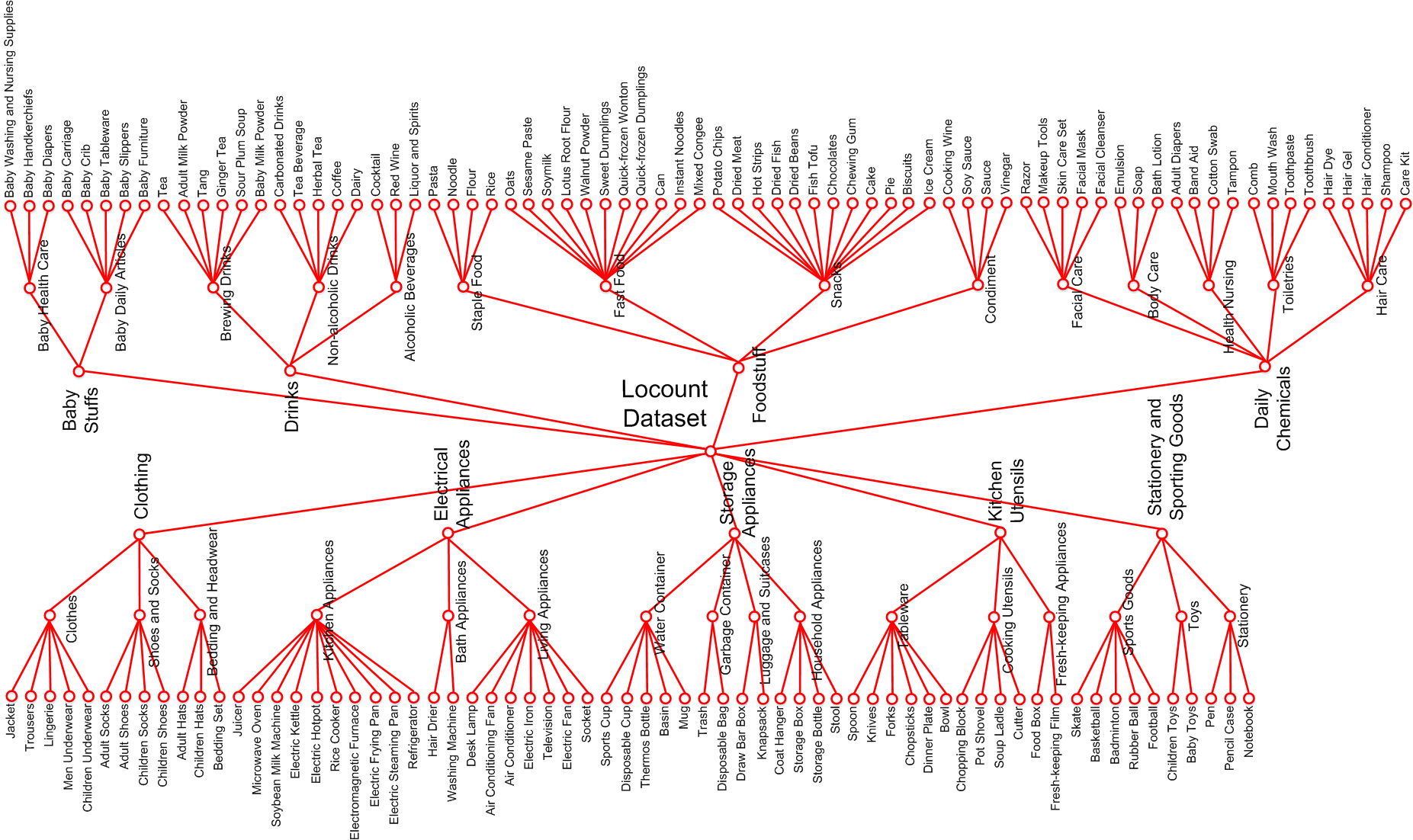
Figure 2: Category hierarchy of the large-scale localization and counting dataset in the shelf scenarios.
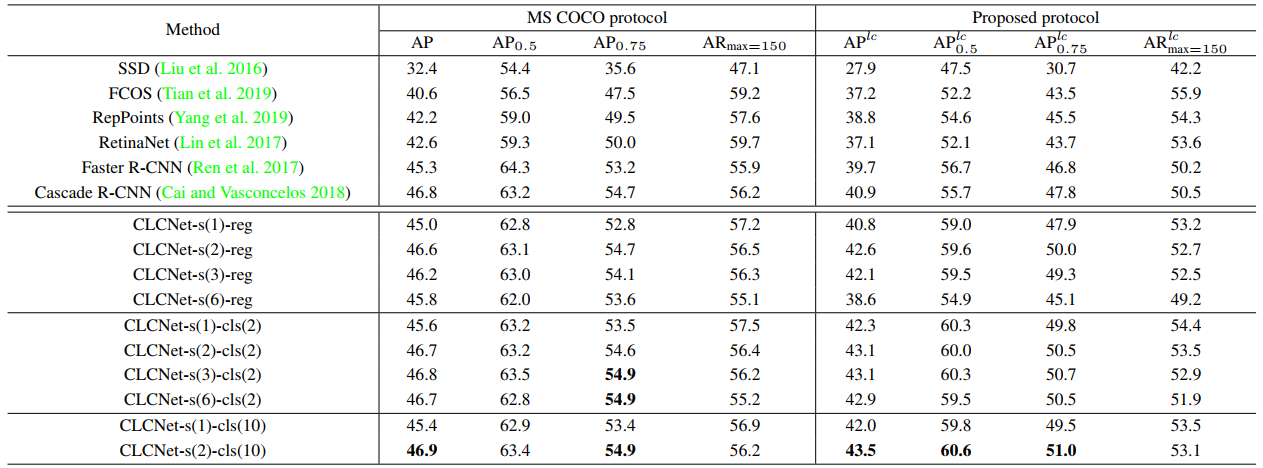
## Evaluation protocol To fairly compare algorithms on the *Locount* task, we design a new evaluation protocol, which penalizes algorithms for missing object instances, for duplicate detections of one instance, for false positive detections, and for false counting numbers of detections. Inspired by MS COCO protocol, we design new metrics *AP^{lc}*, *AP_{0.5}^{lc}*, *AP_{0.75}^{lc}*, and *AR^{lc}_{max}=150}* to evaluate the performance of methods, which takes both the localization and counting accuracies into account. For more detailed definitions, please refer to the [paper](http://arxiv.org/abs/2003.08230). ## Baseline method We design a cascaded localization and counting network (CLCNet) to solve the *Locount* task, which gradually classifies and regresses the bounding boxes of objects, and estimates the number of instances enclosed in the predicted bounding boxes, with the increasing IoU and count number threshold in training phase. The architecture of the proposed CLCNet is shown in Fig. 3. The entire image is first fed into the backbone network to extract features. A proposal sub-network (denoted as ''S_{0}'') is then used to produce preliminary object proposals. After that, given the detection proposals in the previous stage, multiple stages for localization and counting, i.e., S_{1},..., S_{N} are cascaded to generate final object bounding boxes with classification scores and the number of instances enclosed in the bounding box, where N is the total number of stages. For more detailed definitions, please refer to the [paper](http://arxiv.org/abs/2003.08230). The counting accuracy threshold for the positive/negative sample generation is determined by the architecture design of CLCNet, which is described as follows.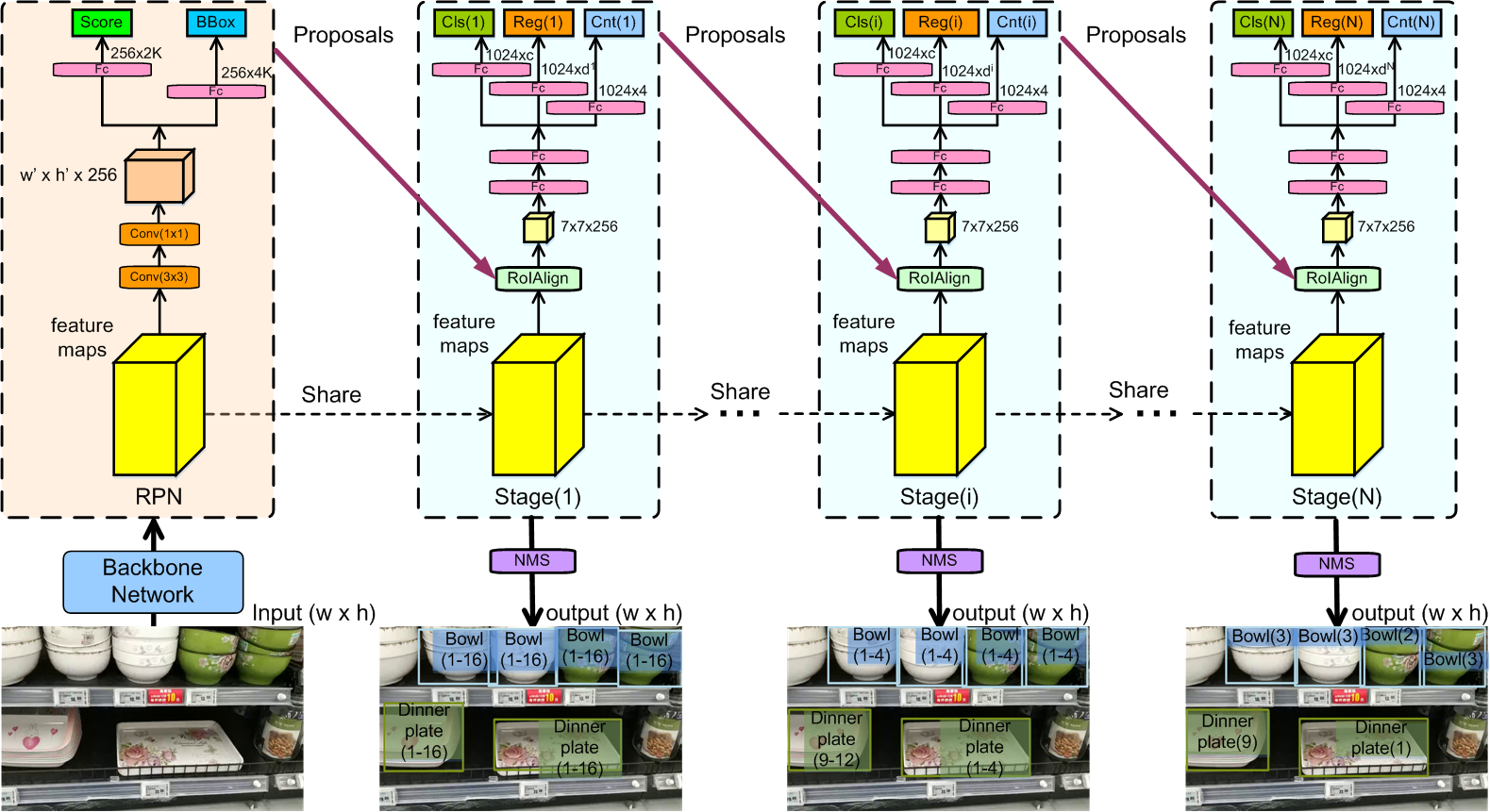
Figure 3: The architecture of our CLCNet for the Locount task. The cubes indicate the output feature maps from the convolutional layers or RoIAlign operation. The numbers in the brackets indicate the range of counting number in each stage.
We use the same architecture and configuration as Cascade R-CNN for the box-regression and box-classification layers. For the instance counting layer, a direct strategy is to use a FC layer to regress a floating point number, indicating the number of instances, called *count-regression strategy*. However, the numbers of instances enclosed in the bounding boxes are integers, leading challenges for the network to regress accurately. For example, if the ground-truth numbers of instances are 4 and 5 for two bounding boxes, and both of the predictions are 4.5, it is difficult for the network to choose the right direction in the training phase. To that end, we design a classification strategy to handle such issue, called *count-classification strategy*. Specifically, we assume the maximal number of instances is *m* and construct *m* bins to indicate the number of instances. Thus, the counting task is formulated as the multi-class classification task, which use a FC layer to determine the bin index for instance number. We conduct several experiments of the state-of-the-art object detectors and the proposed CLCNet method on the proposed dataset, to demonstrate the effectiveness of CLCNet, Table 2 and Fig. 4.